Utilising Hexagonal Architecture for Rust Based Ephemeral Compute

I am a Lead Consultant at Cognizant Servian, with a diverse industry background ranging from startup scale embedded IOT and Industry 4.0 through to enterprise scale Edutech companies and utility providers. My expertise lies in cloud native, secure software development, with a keen interest in exploring emerging technologies.
This isn't the blog post where I tell you why to use serverless Rust, as that's been done already:
AWS re:Invent 2023 - Keynote with Dr. Werner Vogels (youtube.com)
aws-samples/serverless-rust-demo: Sample serverless application written in Rust (github.com)
Instead, we will be looking at how to write Rust, a low-level language, whilst preserving the maintainability, testability, and sanity of your code base. If you're only just starting out on serverless Rust, I recommend you look at my earlier article Simple Rust-based AWS Lambda Functions (ziegelaar.io).
Introduction
Since Alistair Cockburn's seminal article on Hexagonal Architecture the systems we use to build software have evolved greatly. However, the same patterns can be used across systems that use ephemeral computing and emerging languages. My vision for this article is to present a methodology that allows for the Ports and Adaptors approach to software design to be applied to Rust-based ephemeral compute on AWS Lambda. To achieve this, we are going to look at the initial hexagonal architecture patterns and see how they relate to single-purpose lambda functions. We will then build a theoretical model for hexagonal architecture with Rust-based Lambdas. Finally, we will implement a simple service that uses the pattern to provide an HTTPS interface for a serverless application with a DynamoDB persistence layer. In the end, I will leave you with a pattern and template for the service we've constructed in this article for use in your endeavours.
Traditional Hexagonal Architecture
To start with let's take a look at how a traditional hexagonal service might be implemented.

In this scenario, we have a simple service that presents an HTTP endpoint, this is provided by the HTTP adaptor, which likely wraps a framework to provide serving, routing and middleware capabilities. The data then travels through the HTTP port to the core which allows for any business-specific logic to be performed, this might include fetching data from or persisting data to the database through the persistence port and the database adaptor. Finally, we might send some data off to an eventing service for consumption by other services. When we are talking about an independent service these adaptors service many different functions. A database adaptor might have a pool of connections to the DB, and the persistence port presents a repository-style interface to the core.
Serverless Hexagonal Architecture
When we switch to serverless single-purpose lambda functions we get a great number of hexagons. Here is where we need to be judicious with our use of ports and adaptors.
To start with, our HTTP ports become much simpler, as complexity is shifted out of our controller layer to our infrastructure, instead, our hexagons typically have a single entry point. Due to this simplicity, it may be tempting to do away with the port and adaptor altogether. However, this is a false economy, as it will greatly limit the portability of our code to disparate architectures, and if we scale to a point where long-running services make sense again then we can simply replace the transparent HTTP adaptor with a web framework of our choice and combine our hexagons into multifunctional services again.
On the persistence side, a repository for all of our data models seems like a large overhead to manage across a fleet of single-purpose functions. This is where we can leverage the traits system of Rust. We define our data models in our core, our port then defines traits that persist or fetch those data models, and our adaptor is our concrete implementation for those traits, which talk to the external service. There will still be a stripped repository object for our single table design, but it will be supplying generic methods for our model implementations to use. In this way we can peel back the layers of our architecture to replace functionality at any stage, remaining true to the premise of hexagonal architecture, whilst not having to port a large repository across multiple code bases. It is important to recognise that the models, their traits, and implementations are portable though so that the core of any function can rely on any model.
Finally, we might have a global shared port and adaptor tool platform, like the eventing port and event bridge adaptor, that provides common functionality across all functions.
Under this new paradigm, we can now draw out our serverless hexagonal architecture:
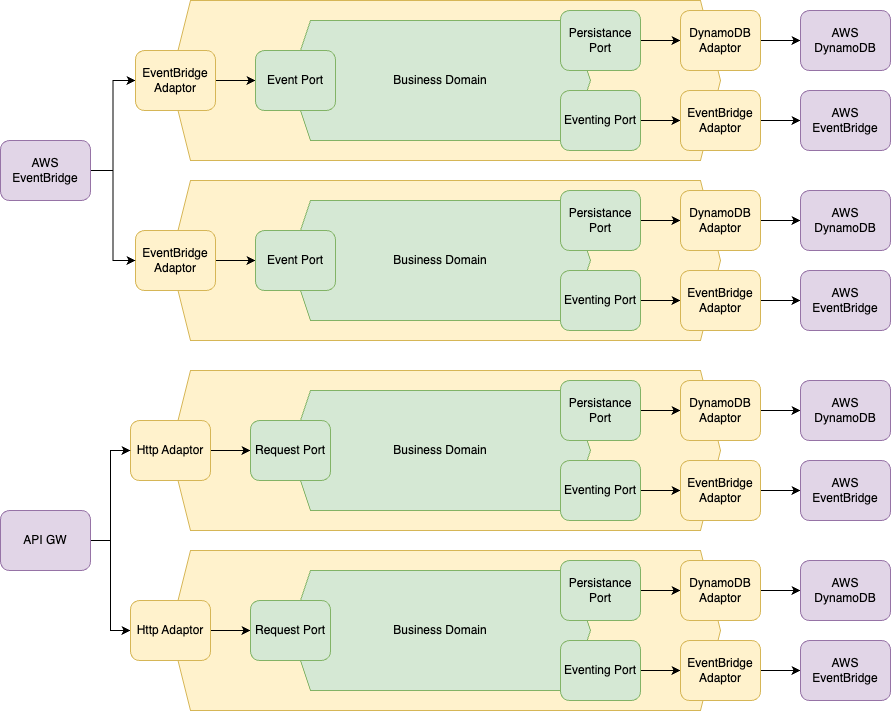
Our services now consist of multiple hexagons that are tightly scoped to the resources we need to access. Things like the HTTP adaptor, and EventBridge may be completely shared functionality across all hexagons, whereas modules containing models for persistence may be independently consumed by their related service.
I still like to maintain the concept of a "service" even in the serverless realm, so a collection of functions that all share a domain create a service. Otherwise, we end up with a tightly coupled monolith, deployed as a series of atomic lambda functions, that is likely even harder to refactor than a traditional monolith due to the added infrastructure complexity.
Project Layout
I like to use a mono-repo for as long as is practically possible for any project, internal dependencies are resolved immediately, common functionality is easily extractable, and features that run across services can be managed and synchronised centrally. The downside is that it requires discipline, your dependency tree should only be from higher-order objects down, never horizontally or (even worse) vertically up. A good example is that it is fine for a service to depend on functionality in a common library, but a service should never depend on code present in another service, or a common library should never depend on code residing in a service.
The other important feature that I like to enforce is centralised dependency handling. There are many tools out there that will allow you to set up independent workspaces that each manage and refer to their dependencies as individual units. Whilst these tools make it easy to do this, it becomes hard to track your Software Bill of Materials (SBOM) and work out what versions are installed where. The advantage of using a compiled language is that if we don't use it, it won't be present in our final binary (in TypeScript I use ESBuild bundling with tree shaking to the same effect). It also enforces a one for all approach, if you update a library for one specific dependency, then you're responsible for making all other dependents compatible, no more silently letting the technical debt accrue. Rust workspaces are very forgiving in the way that they resolve shared dependencies between packages and a single "Cargo.lock" file is useful for SBOM. However, I prefer the root specification alongside dependent inheritance, rather than specifying the package version in all of the dependencies and letting Cargo resolve them, for ease of management.
I won't dive into the detailed structure of the project here; you can check out the GitHub repo for that, but I will go through an example business domain problem. Let's take the example of clearing a user's cart, there are two scenarios where we are interested in doing this:
The user has requested for their cart to be cleared.
We receive a user deleted event from the user service
In this scenario we actually have the same business logic, the only thing that changes are the ports and adaptors connecting the event / request to the business logic. To do this we build two entry points, one EventBridge adaptor and one API Gateway HTTP integration adaptor, then register them both as targets in the services Cargo.toml.
[[bin]]
name = "cart_clear_http"
path = "cart_clear/http_adaptor.rs"
[[bin]]
name = "cart_clear_user_delete_event"
path = "cart_clear/eventbridge_adaptor.rs"
We can now take a look at the cart_clear folder and see the upstream adaptors and ports.

I won't dive into the code itself, but we can visualise the way the particular action is compiled here:
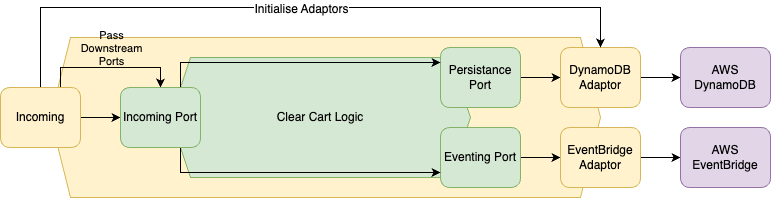
At the top level of the incoming port, we initialise everything that the business domain needs. This includes the cart repository for DynamoDB and the EventBridge Adaptor. These adaptors conform to port specifications defined as Rust traits. The incoming port performs validations and port specific validation, then sends the information down to the core Clear Cart logic. The ports and core logic are only ever aware of the shape of the ports the actual implementation and instantiation of the adaptors happens at the entry point to the system.
Testing It
The ability to test our code is crucial, and while it may look like we've created a whole lot more effort for ourselves from a testing perspective, what we've actually done is given ourselves a very clear separation of concerns. The core logic can be unit tested in Rust directly, with mock implementations of the ports that simulate the response from the adaptors that implement them. This is what is present in the repo when you run make test-rust. On the other hand, all of the messy cloud part that we usually need to mock out is now nicely contained in our adaptors. I'm a big fan of testing in the cloud rather than testing for the cloud. What I mean by this is its much better to run a suite of tests against actual deployed infrastructure, rather than against a simulacrum of the cloud that may or may not be based in reality. When it comes to serverless architecture this is even more achievable as the costs for an ephemeral environment are minimal. This is exactly what we do in our example repo, we can run our unit tests, create an ephemeral environment, run our integration tests, and tear down that environment, all within the space of a few minutes, with a single makefile command. This is, in my opinion, the best way to test your adaptors, by black box testing your application in an ephemeral environment and ensuring that the state transitions you are expecting, actually occur.
The Verdict
Rust is strict and can be messy, but using hexagonal architecture allows us to structure our serverless Rust code in a way that is easily understandable, testable, and runnable, without running into issues with mocking out large parts of the cloud. To see a sample application, you can visit the GitHub repo for this project here Aiden-Ziegelaar/HexagonalRustLambda (github.com)



